Objective:
We aim to present a systematic approach for fraud detection from data usage. The approach comprises of machine learning methods such as One Class Supported Vector Machine (OCSVM) from supervised learning category.
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/one-class-support-vector-machine
This model was trained to detect few cases of anomalies with high accuracy in a big set of normal data. Thus, the determination of One Class which is identified as class resulting in the variable being an anomaly this belonging to a different set of data than the normal set.
The OCSVM learns what is normal and detects what is not a part of normal.
Data Description
The data has 6 variables and has the dimension of 166734 x 6.
You can download the data from here:
https://dandelion.eu/datagems/SpazioDati/telecom-sms-call-internet-mi/resource/
The observations represent an account holder (ID) as the owner is sending several SMS, doing calls and the internet usage is there in the dataset as well
The data set had the record January 2014.
Feature Engineering
The
features were engineered for anomaly detection by reasoning about the
properties that anomaly samples are likely to have in common and the concrete
features that reflect these behaviours. Feature selection methods can rank a
list of potential features according to their effectiveness.
However, the initial list is the result of a feature engineering process,
involving human researchers who rely on their intuition and knowledge of the
domain.
The feature engineering process is crucial to the effectiveness and applicability of machine learning. The new features are expected to provide additional information that is not clearly captured or easily apparent in the original or existing feature set. But this process is laborious and something of art thus requires researchers to assimilate a growing body of knowledge.
I aggregated the data by ID and expanding the information by spreading the data thus resulting in the availability of more features. Thus increasing the size of features from 6 to 187.
Normal Data vs Fraud Data
Since data is not classified by default, we have to apply rules to define outliers in the data as potential fraud i.e. anomaly
Condition 1: Mean number of SMS Length & Number of Minutes 99.8% quartiles.
Where call duration by an ID is usually long and would be classified as an outlier also when number of calls by an ID is an outlier.
Condition 2: Abnormal data usage by 99.9% quantile.
ID’s focused on abnormal data usage.
Supervised Model – Support Vector Machine
There are not many cases of anomalous behaviour in the data and since the % fraud is low we have to train the model to learn about one class.
When the model has learned about one class which is a normal data, a model will have the capability to identify what is not normal.
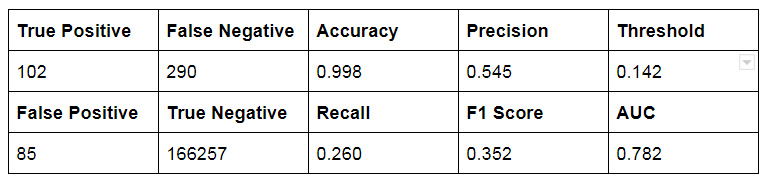
The model was not tuned to detect configuration which results in high accuracy, precision, recall or F1 score. This tuning is defined in the context of the policy dictated by the attitude of business towards fraud.
Therefore, the support vector model is trained on data that has only one class, which is the “normal” class. It infers the properties of normal cases and from these properties can predict which examples are unlike the normal examples. This is useful for anomaly detection because the scarcity of training examples is what defines anomalies: that is, typically there are very few examples of the network intrusion, fraud, or other anomalous behaviours.
Model Performance