

The paper published in 2018 by Scott Fujimoto, Herke Van Hoof and David Meger, mentioned the algorithm which could improve the previously existing algorithms used to train machines maximising value.
Context to how TD3 relates to our own learning experience
Although I am oversimplifying it is still similar to the experience we all go through where we set an objective to learn something and we aim to learn as much as we can in an as little amount of time as possible.
In our personal experience, we go about several different techniques which can potentially improve our learning. In the case of reinforcement learning these techniques are called “learning algorithms”.
Just like our approach to learn a different subject be different, depending on the problems there are different types of learning algorithms. An example of that would be learning to think in abstract vs writing logic in arithmetic.
On the other hand, some techniques are better than what we have used previously, and our approval rating of new techniques come from how they maximise our learning in the least amount of time.
We would regard the learning algorithm to be the best based on its efficiency, despite previous techniques being obsolete they still hold the value because without them we wouldn’t have been able to get to where we are today. This is important because TD3 although is a significant step forward but it builds on top of the model called “actor-critic”.
Briefly explanation of TD3
So, TD3 is a complex algorithm. Which one isn’t! said the people who are aware of the reinforcement learning algorithms.
It consists of 2 are critic models and 2 are critic targets. Similarly, there is are an actor model and an actor target.
The models used in actor-critic are a part of the Q-learning algorithm.
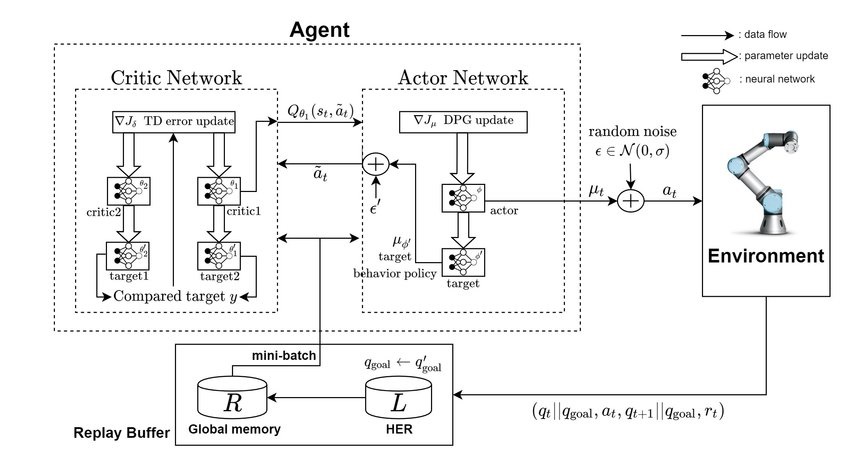
What happens when machine learns from TD3?
Starting from the topic of performance, how does it compare to the previously existing techniques? Let’s have a look at the comparison graphs.
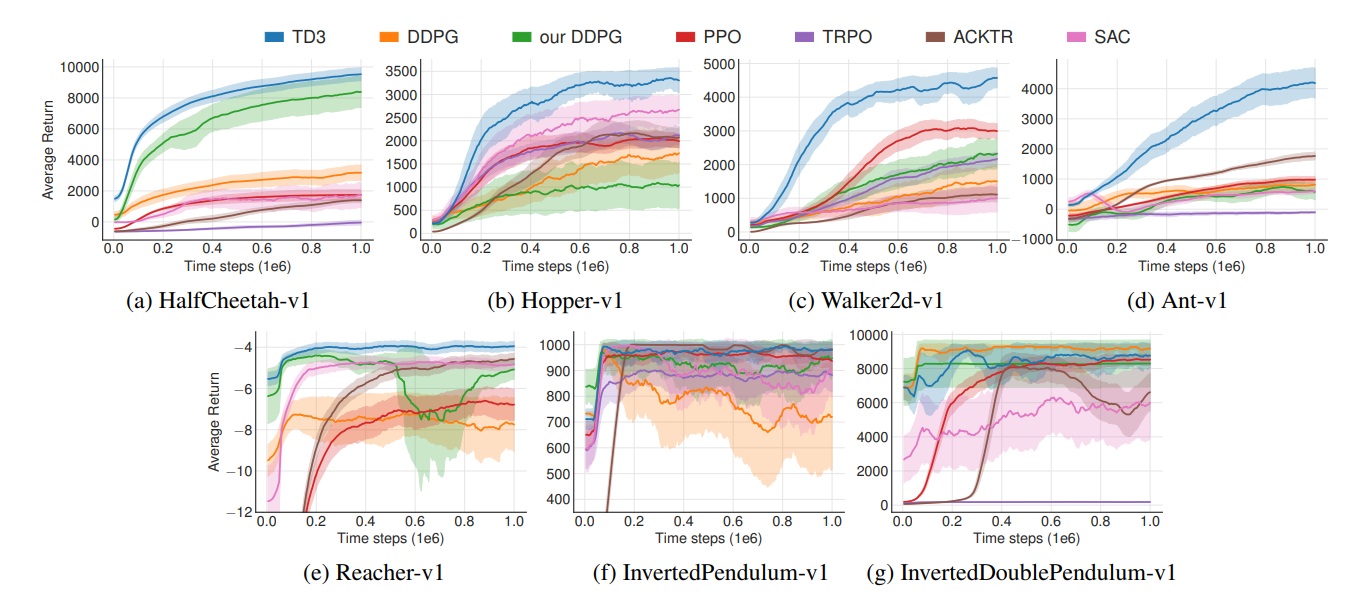
Each graph has time steps on the x-axis and average returns on the y-axis and they have the plot lines of each algorithm with fading background colour as standard deviation and the mean is the bright colour.
Plots represent performances of algorithms in a different environment where the environment for Ant-v1 is the 3rd environment.
The idea represented on each plot is to reach the maximum reward in the least amount of time. The maximum average return in the least amount of time is the success criteria. Hence it is clear from the plots that TD3 boosts significant performance gains as a learning algorithm.
And surely you would like to see what does the export of the trained model would look like, so here it is.